背景
在 AI 时代,获客方式不断翻新——SEO、GEO、达人分销层出不穷。但广告投放依然是最基础、最可控、也最能在短期内拉动规模的增长手段。
投放的分析看上去简单,不过是计算CPA、ROI,衡量一下钱效。但每个做投放业务的人,都会被问到一个问题:“如何证明你拉到的用户,是真的因为投放才会进来的?”
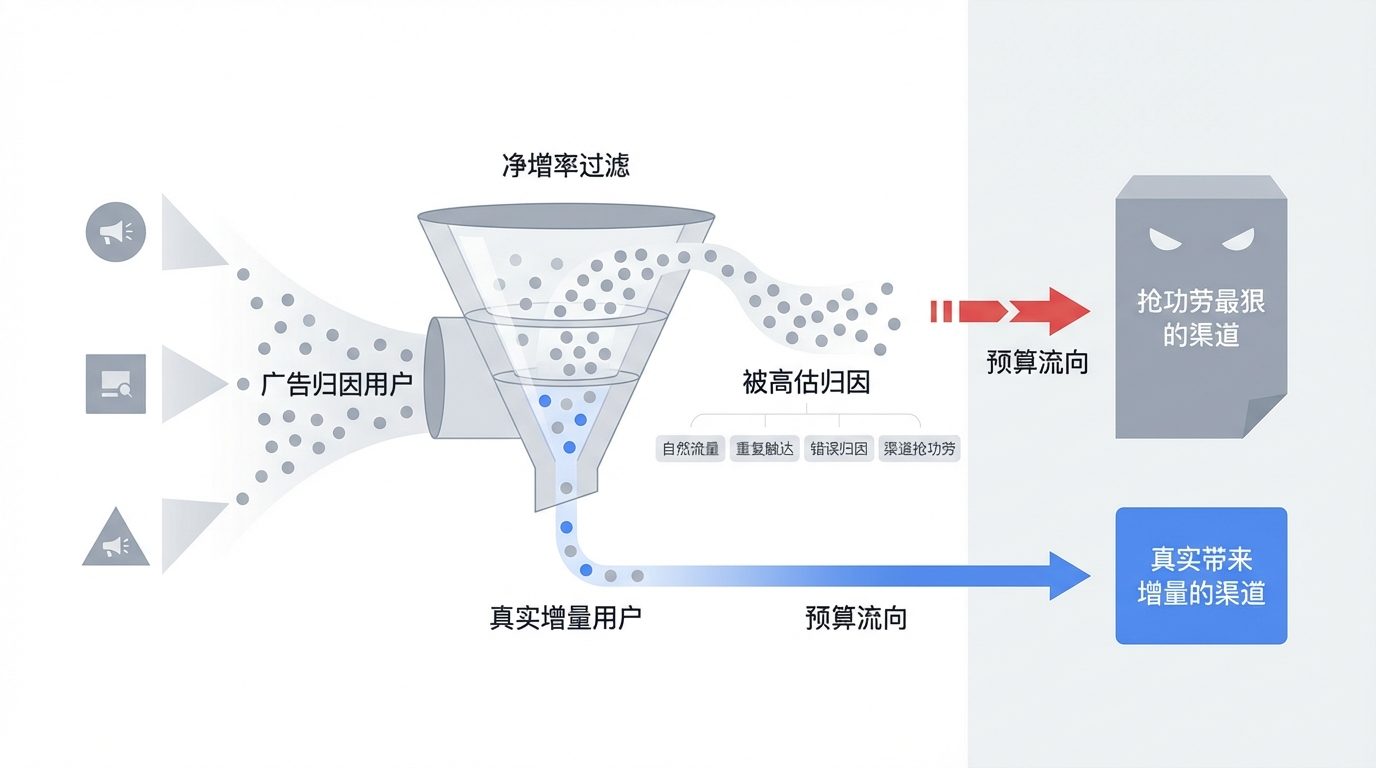
而这就是净增率问题,它是所有投放业务中最麻烦、也最难啃的一环,也是很多投放业务证明自身价值的终极考题。净增率严格的定义是:渠道触达的用户,如果不在该渠道触达,那么就不会通过其他方式,无论是自然还是投放去触达。一句话而言,净增率衡量的,是广告归因给你的用户里,有多少人才是真正属于该广告带来的。
它为什么重要?因为如果不剔除这部分,渠道 ROI 会被系统性高估,预算一般会流向"抢功劳最狠"的渠道,而非真正带来增量的渠道。而它为什么难测,一方面是因为很多媒体平台会主动撞自然流量来冒领归因,让表面数据更加失真;另一方面是很多投放的渠道本身就是自然/买量混合的,例如搜索品牌词的广告位,本身就是极难拆分的。
笔者在几家公司做投放方向的数据分析时,都反复遇到过各种计算净增率的问题,而本文是对各类净增率测算方法的系统梳理,希望能对这类问题有一个较为系统的解释。
计算方法
对于不同的渠道,其计算净增率的方式也各不相同。我们按计算的约束从小到大,可以分为三类:
约束最小:RTA 分流
现在大部分的流量平台,都配置了RTA:当媒体平台准备向某个用户(设备)展示广告前,会先将该用户的设备号(如 OAID、IMEI、IDFA 或其 MD5 加密值)实时推送到广告主的服务器。广告主在极短时间(通常为 50-100 毫秒)内进行内部运算,并向媒体返回“是否参与竞价”或“出价策略”的指令。
而基于媒体提供的设备 ID,广告主就可以进行精准的流量分流(可以理解为是站外的AB实验),例如可以设置为:
- 5% 的流量设为永久 holdout 组,始终不投放(用于测算不投广告带来的长期影响)
- 95% 的流量为大盘组,其中抽取10%设为屏蔽组,剩余85%正常投放,每隔一段时间打散流量

通过观察被屏蔽用户,是否从其他渠道或自然量中回流,从而得出净增率。但注意,这个净增率往往是产品级的,而非渠道级的。这是因为一个用户会在多个渠道和自然量间流转,而实际的竞价广告生态又是一个动态博弈系统,我们无法测算“假如在A渠道不投,那么在B渠道获取该用户的边际概率”。所以产品级的实验是全局留白的,得到所有广告渠道的整体 Uplift,进而算出整体广告投放对自然量的侵蚀情况。
而为了计算出渠道级别的净增率,我们就需要看得更细,看到渠道之间的影响幅度。让我们回到投放的核心指标ROI,它等于 ,而在这个问题中,我们需要计算的是每单次投放的增量价值,它等于
其中 边际CPA代表通过其他渠道获取该用户的机会成本,进一步拆解:
- :微观个体的非净增的概率,它是由实时预测模型根据该用户的特征(如设备属性、历史行为等)算出的,代表当前这个特定用户本身会自然来访的比例。
- :对渠道 的宏观非净增率(联合概率)。通过大盘净增实验得出,代表当前渠道“抢夺”了渠道 多少比例的流量。
- :宏观大盘总非净增率(边缘概率)。通过大盘净增实验得出,代表当前渠道整体上“抢夺”了外部多少比例的流量。它满足 。
- :非净增用户的流向分布(条件概率)。代表在“已经确信用户非净增”的绝对前提下,该用户具体流向替代渠道 的概率。
通过这个复杂的公式,我们最终就能计算出具体到单个渠道的钱效,甚至可以下钻到“单次广告曝光”粒度的。但是这个公式显然也是有一些不足的,它最大的不足是:
- 对投放规模有要求,存在显著的时效滞后性:这套基于条件概率的计算公式,在统计学上极其敏感,需要较大的数据量才能稳定下来。业务团队往往需要拉长观测周期,等数据平滑后才能得出结论。
- 宏观分布与微观个体的“生态谬误”:公式在计算期望成本时采用了较为粗暴的均值分配逻辑,但是在真实场景中,不同意图用户被投放抢夺的路径是高度异构的。例如,一个模型预测净增概率仅 10% 的高意图用户,如果不在该渠道转化,他极大概率会直接去应用商店下载,而非去信息流里点击广告,这在一定程度上会导致部分人群的计算失真。
尽管有上述这些不足,这套公式依然是我所知道的,目前计算净增率最常用的公式,它结果直观、计算快速,能完美适配毫秒级 RTA 的竞价环节,是一个非常漂亮且务实的“工程级近似优解”。
约束中等:停投实验
说完了上面可以做RTA分流的渠道,接下来是一些虽然无法做精准分流、但是支持停投/复投实验的场景了,例如:
- 一些未接入 RTA的渠道,比如达人投放、地推、小的流量平台、地区类的广告媒体
- 流量规模不够做实验的场景(毕竟第一类实验需要足够大的流量才能置信)
面对这种无法做分流实验的情况,我们一般有两种操作方式:
- 局部停投(准实验): 选取体量、趋势、量级接近的两个地区 A 和 B,在 A 停投、B 不停,观察差异。
- 全量停投: 直接停掉该渠道,观察自然量的回升幅度。
| 局部停投(假AB+地理位置隔离) | 全量停投 | |
|---|---|---|
| 方案原理 |  |  |
| 实验设计 | 地区筛选:计算不同城市、国家在过去一段时间的业务数据相关性 配对:选取两个趋势高度一致的地区,例如广东 vs 浙江或者德国 vs 法国: 1. 给出 Region A 作为停投组:停止该渠道投放 2. 给出 Region B 作为常态组:保持原有策略投放 周期建议至少 2-4 周,以覆盖完整的转化窗口期。 | T0(Baseline阶段):记录过去两周的总新增量、自然新增量。 T1(Blockout):瞬间切断渠道的所有预算。 观测指标:观察大盘总量是否下跌,以及自然流量是否出现明显的台阶式上涨。 判断逻辑: 1. 如果大盘总量几乎没跌,且自然流量暴涨,那么净增率就极低。 2. 如果大盘总量也在暴跌,自然流量纹丝不动,那么净增率就极高。 |
| 前置条件 | 市场同质性:需要找到体量、自然流量占比非常接近的两个市场,保证可以用不同地区去预测停投地区 平台能力:广告平台要支持地理定向的能力 无跨区干扰:确保广告不会产生严重的溢出效应 | 决策层支持:需要能够承受短期内业务量可能大幅波动的风险 环境稳定:必须避开大促、节假日或产品大更新的时间,确保时间序列上没有其他大的变量。 |
两种方式面临同一个建模的问题:如何预测"如果没有停投,自然量本来会是多少"。这部分,我们通常采用反事实推断模型来解决(比如 Causal Impact)。
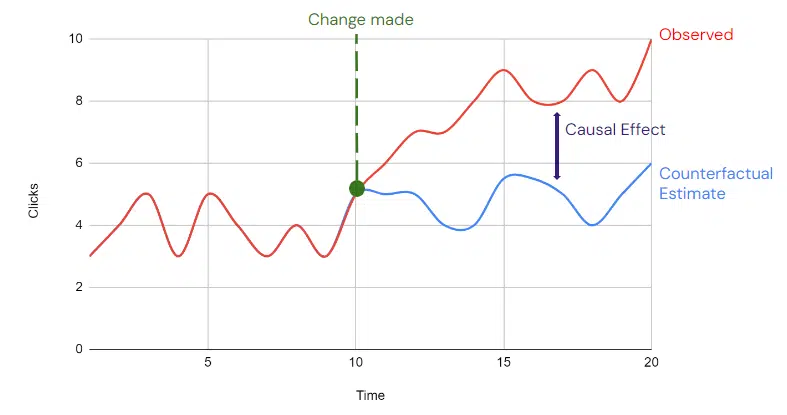 该模型的关键在于找到合适的协变量 X——它必须与自然量强相关,但与投放量无关。业务中常选用的协变量包括:其他地区的新用户量级、Google/百度/微信搜索指数、SEO 数据、B 端量级等。
该模型的关键在于找到合适的协变量 X——它必须与自然量强相关,但与投放量无关。业务中常选用的协变量包括:其他地区的新用户量级、Google/百度/微信搜索指数、SEO 数据、B 端量级等。
约束最大:预装
考虑完上面两个场景,那我们来到了一个最难的场景,它既无法做分流,也不能停投,一旦合同签下就以年为单位全面生效,预装。
这是所有渠道中净增率最难测算的,即便是投放预算极高的头部大厂,也很难精确算出每个机型的净增率。甚至好多时候不同部门、不同方法计算出的结果,差异可能极大。笔者曾经在一家大厂负责投放预算规划,每年计算的预装净增率都会被各方挑战N次。这里介绍两种我曾经尝试过的方法:
方法一:数据建模,上算法。借助 RTA 实验中得到的一系列后验指标(如换机率、用户首次入网时间、长期留存等),找到与净增率高度相关的特征,建立组合模型,预测每个预装渠道的净增率。
方法二:准实验 + 分布滞后模型。 首先,获取每个机型的出货量。因为出货->用户激活往往有较长时间滞后,需要通过一个分布滞后模型,将出货量转化为各周期真实的“活跃新机量”作为测算基数; 其次,寻找可能的实验组,如同一类型但未预装的机型,或是曾经预装但后来停装的机型,利用无干预期的纯净数据标定出两者固有的转化系数; 随后,将此系数映射至预装的机型上,以此对冲并剥离宏观市场热度、季节性波动与大盘营销投放带来的时序噪音,逆向推导出目标设备若未实施干预时的“理论自然新增底盘”。 最终,利用这一反事实的自然增量除以报表实际归因的预装总增量,实现对预装渠道真实净增率的定量解构与客观测算。
预装的投放,在各种算法之外,高度依赖商务的谈判能力、领导层的决策、竞对的投放策略,这些都是数据所不能及之处了。
结论
经过净增率修正后,我们会看到各渠道的真实 ROI 排序与表面数据出现了显著差异。部分看似高效的渠道实际增量贡献有限,而一些此前被低估的渠道反而展现出更强的真实获客能力。这往往会直接改变后续的预算分配的优先级,也改变了对不同渠道的考核方式。