
一句话概述
一个从个人脚本长出来的内部生产力工具,一个由AI 驱动全栈开发的正式产品,打标周期从 1 周压缩到 1 小时。
网站链接: https://www.klabel.org
一、发现需求:问题怎么来的
我在做视频生成质量的分析时,需要对用户上传的 Prompt、图片和视频进行大规模打标,判断创作意图、风格偏好等,再与后续的多次编辑、下载等行为交叉分析,获取用户在不同类型任务上的满意度。最关键的打标步骤,我一直是自己用AI来编写代码去完成的。
但跟组内其他分析师沟通时,我发现他们在打标这件事上很痛苦。传统的打标流程是“对齐标签树->协调打标人力(实习/外包)->获取结果并分析”,长的话可能要一到两周。
当我去询问他们,为什么不直接写个代码,用LLM来打标时,发现他们有两个难点:
第一,认知问题。大多数分析师对 AI 的理解还停留在"对话工具"阶段。他们不知道什么是API调用,什么是让模型批量完成结构化打标。
第二,技术问题。即便有些人会写 Python,也不熟悉 API 调用和接口对接。AI Coding 这类工具,他们也不了解。
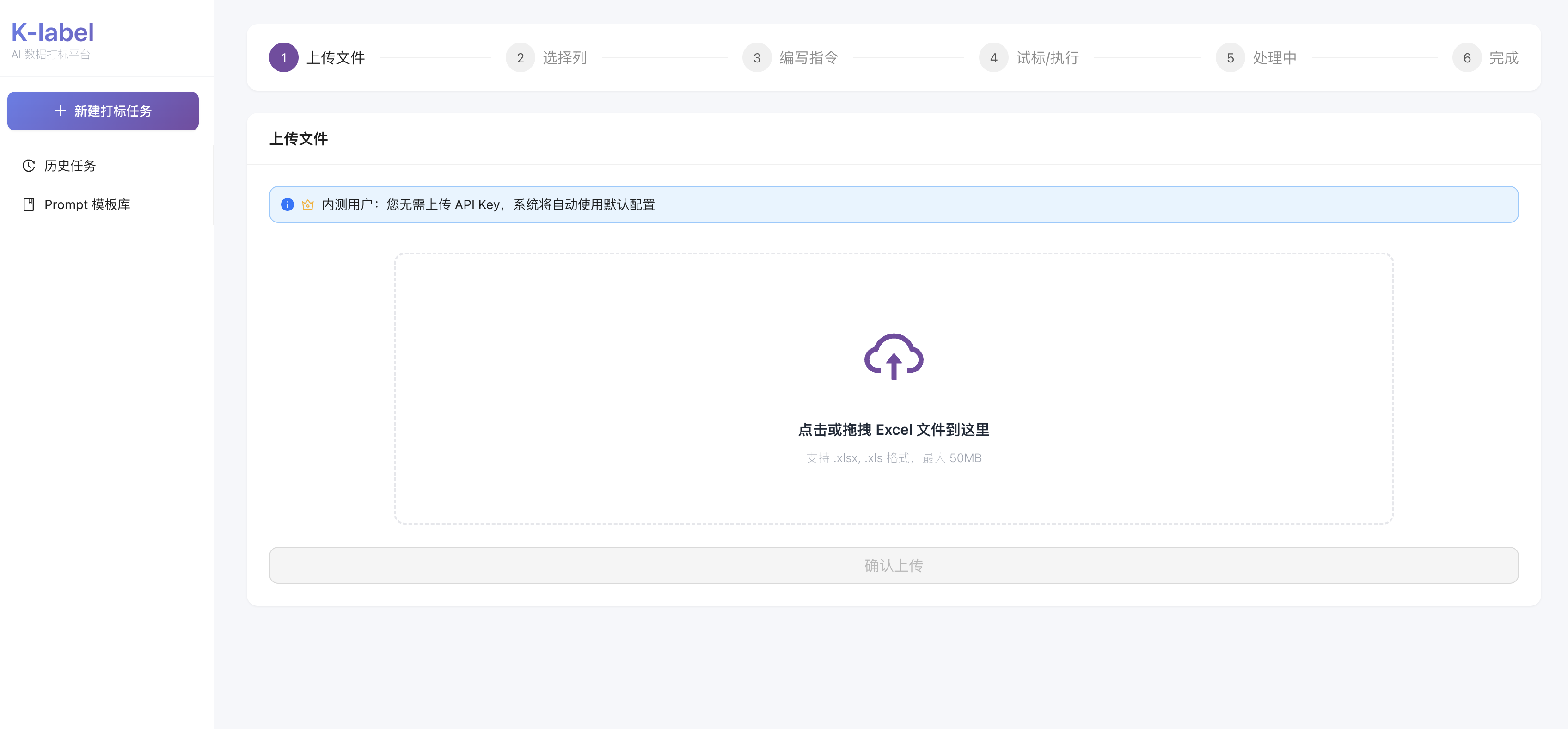
我意识到这个问题可以产品化。对分析师来说,理想体验应该是:上传 Excel,写好 Prompt,点击运行,拿到结果,所有技术的复杂度不该暴露给他们,这也就是“可标”最初的愿景。
二、MVP搭建:哪些功能是重要的
我的打标脚本是确定的,但一旦决定要做成产品,我就不可避免地开始多想,还需要加上哪些功能呢?我花了一下午的时间和AI一起畅想,一个好的打标工具需要满足哪些功能。我列出了当时我觉得比较重要的一些模块:
| 功能 | 核心内容 | 要解决的问题 |
|---|---|---|
| 提示词补全与任务配置 | 标签体系配置、标签说明、边界条件定义、任务模板、Prompt 自动补全 | 把用户模糊需求变成可执行的打标任务 |
| 模型执行与调度 | 多模型接入、动态模型调度、多阶段打标、低成本模型初筛、高质量模型复判 | 在准确率、速度、成本之间取得平衡 |
| 结果输出与结构化 | 标签输出、理由/证据输出、结构化 JSON、原表回填、结果导出 | 让打标结果可以直接被业务使用 |
| Human-in-the-loop | 在线修改标签、错误原因反馈、一键重跑、人工复核池、低置信度样本优先复核 | 当模型不准时,可以高效修正和补救 |
| 学习与优化闭环 | 用户纠错样本沉淀、正反例库积累、Prompt 优化、主动学习、历史任务复用 | 让系统随着使用持续变好 |
除了功能外,我还在思考整体的技术选型。由于当时我正在学习 Agent 相关的课程,我自然第一时间想到的就是:把这个做成一个Agent 驱动的产品。于是我手搓了一个简易的ReAct框架,实现了:“用户输入简易的提示词->识别用户意图->调用各类工具(prompt补齐、模态识别、文本/图片/视频打标)->返回结果”的全过程。
这里面最有业务sense的,其实是prompt补齐的部分。一个好的打标prompt,需要满足诸多条件,例如分类树是MECE(完全穷尽、相互正交)、要有边界case的定义、要有优先级的判断、要设定约束,最好还能给出打标原因。我把他封装成了一个简易的skill,放在了工具里。
一周后,我拿着做好的MVP,给到了几位同事体验。他们给到了一些很直接的反馈,整体的产品体验和用户流程设计是他们需要的,但是提示词补齐是不需要的,因为他们想要更好地直接控制输入。动态模型调度/多阶段打标也是不需要的,但是多模态融合/一次打更多的列是需要的,能够手动选择不同的模型去double check也是需要的。
于是,有了这些输入后,我就正式确定了最终的产品形态,进入到了开发的过程。
三、正式开发:前后端+数据库+云部署
在此之前,我已经写过非常多的 side project,对于前端开发所需要的技术栈以及相关情况都已经很熟悉了。但是涉及到后端,我的经验就没有那么充足。Coding 工具在后端上的表现远不如前端那么惊艳,如果涉及到数据库设计,就更为头疼了。
为了解决这个问题,我和 AI 进行了详细的框架讨论和设计,它给我列出了非常多的备选项,然后根据我这个项目的使用情况进行挑选。并且按照 vibe coding 中“文档优先”的开发原则,在进行整个后端开发前,我让 Gemini 调研并提供了一份非常全面的PRD,尤其是涉及到框架选型的。
| 层级 | 选型 | 选型理由 | 舍弃的选型及原因 |
|---|---|---|---|
| 前端框架 | React | 适合做内部管理后台和复杂交互页面,生态成熟,和 Ant Design 搭配顺手。团队内部使用、规模不大,优先选择稳定高效的方案。 | Vue、Next.js:也能做,但对于一个小的内部工具价值不大。 |
| 前端 UI | Ant Design | 非常适合中后台和协作平台,表单、表格、弹窗、权限页这些组件现成,能快速搭建内部工具。 | Tailwind + 自建组件:灵活但开发成本更高,不适合当前内部工具优先上线的目标。 |
| 后端框架 | FastAPI | Python 生态友好,开发快,接口清晰,适合接 AI 能力;并发不大的情况下,不需要为了极限性能上更重的框架。 | Django:更重,很多能力当前用不上;Flask:太轻,工程化能力弱;Go/Gin:性能更强,但对当前低并发、偏 Python 的场景收益不大。 |
| 主数据库 | Cloud SQL for PostgreSQL | 更适合“关系型 + 半结构化”混合场景:既有标准表结构,又会有模型输出、标签明细、扩展字段这类不完全固定的数据。PostgreSQL 原生就有 json/jsonb 支持,这一点很贴合 AI 打标系统。 | MySQL:也可以,但 PostgreSQL 对复杂结构和扩展更友好;MongoDB:更适合文档优先的系统,不适合当前这种任务/权限/项目的关系型数据库。 |
| AI 调用层 | Google Vertex AI、deepseek | gemini的VLM理解能力强,极其适合用来做视频生成的打标任务 | 出于采购限制的原因,只选用了两类模型;Qwen在计划添加的名单上 |
| 后端部署 | Docker + Google Cloud Run | 容器化清晰,部署简单,适合内部工具;并发不大,不需要上更重的方案。 | Kubernetes:太重,对于团队级的产品来说不值得;传统 VM 手工部署:可行,但运维更麻烦;纯 Serverless Function:不适合媒体处理和较复杂后端服务。 |
| 前端部署 | Firebase Hosting | 很适合托管 React 静态页面,接入简单,部署快,适合内部前端站点。 | Vercel:也可用,但既然后端和 AI 都在 Google 生态,继续放 Google 体系更统一。 |
| 异步任务机制 | 先用 PostgreSQL 任务表 + Celery | 异步任务明确存在,但用户少、并发低,可以先用轻量方案,不必一开始就上复杂队列系统。 | Celery + Redis:后续任务量上来再加更合适; |
| 用户认证 | Google 登录+内测码认证 | 仅供公司内部使用,用户人数少,接入成本低; 由于组间的预算是分离的,所以组内的同学使用内测码注册后就可以直接用本组的key,外组的同学可以选择上传他们的key。 | 自建账号密码:开发和维护成本更高,内部工具没必要; |
整体的流程图:
明确了上面的框架选型之后,我就开始做完整的开发。在此期间遇到了很多的bug,但在Claude Code的帮助下,基本是遇山开山、遇水搭桥,一步步解决问题,在这期间我也学会了很多技能,让我对于很多工具、技术的上下限有了更清晰的认知,对于agent的演进、产品形态的设计也有了独立的判断。
四、持续精进:产品迭代+运营
当这个产品完全开发上线之后,下一步做的就是把这样的一个工具给 sell 出去,做一个公司内的用户增长工作。这当然也是一件很有意思的事情,在一些组会和内部分享会上,我分享了这个产品如何使用及其开发过程。除了数据分析师外,我还提供给了PM、运营和评测团队。
通过倾听他们的诉求,在此期间我收到了很多非常多的反馈,并据此进行了持续的产品迭代。有很多我之前没有想到的功能都一一做了迭代:
- 上线了"试标"功能。用户可以先用低成本模式测试少量样本。一是在全量打标前预估总成本,避免预算失控;二是检验 Prompt 写得准不准,防止跑完整批数据后才发现效果不达标。
- 支持直接在网页内逐条回查每个打标 case,省去下载 Excel 再人工核对的步骤。
- 自动生成打标结果的基础统计指标、分布直方图、置信度等指标,让PM、分析师第一时间判断结果质量
- 上线了模板库,保存和复用常用打标配置
最难的一次迭代来自模型数据团队的一个需求,他们要判断train dataset和线上用户数据之间的分布情况,要做非常细致的标签结构,这涉及到十几个标签树,很多标签树的深度达四级,最多有 700+ 个节点。如果把标签树直接转化为prompt,那就会撑爆上下文窗口,导致打标结果出现大量幻觉。为此,我专门设计了"级联打标"机制,支持用户直接上传完整的标签树 Excel,系统按层级逐步打标,解决了超长标签体系下的稳定性问题。
对我意味着什么
这个项目的起点不是产品需求,而是我作为数据分析师干活时观察到的团队痛点。从发现问题、验证需求、开发上线到持续迭代,我独立跑完了一个产品从 0 到 1 的完整周期。
这个过程让我意识到:数据分析师的边界也可以不止于"出报告"和"提建议"。当你具备用 AI 把想法变成产品的能力,你既是问题的发现者,也是问题的解决者。
在整个项目推进的过程中,我深刻体会到了“做属于自己的事情”才是最有动力的,我享受作为 AI Builder,将自己的判断与想法真正做成产品的过程。我越来越确认,我想成为一个“既懂业务与产品、又能亲手把事情做出来”的人,而非只是担任数据分析师这一职位。